RAG LangChain Implementation
Working with these articles:
- Getting Started with Weaviate: A Beginner’s Guide to Search with Vector Databases | by Leonie Monigatti | Towards Data Science
- Retrieval-Augmented Generation (RAG): From Theory to LangChain Implementation | by Leonie Monigatti | Nov, 2023 | Towards Data Science
This note goes on to showcase how you can implement a simple RAG pipeline using LangChain for orchestration, OpenAI language models, and a Weaviatevector database.
What is RAG
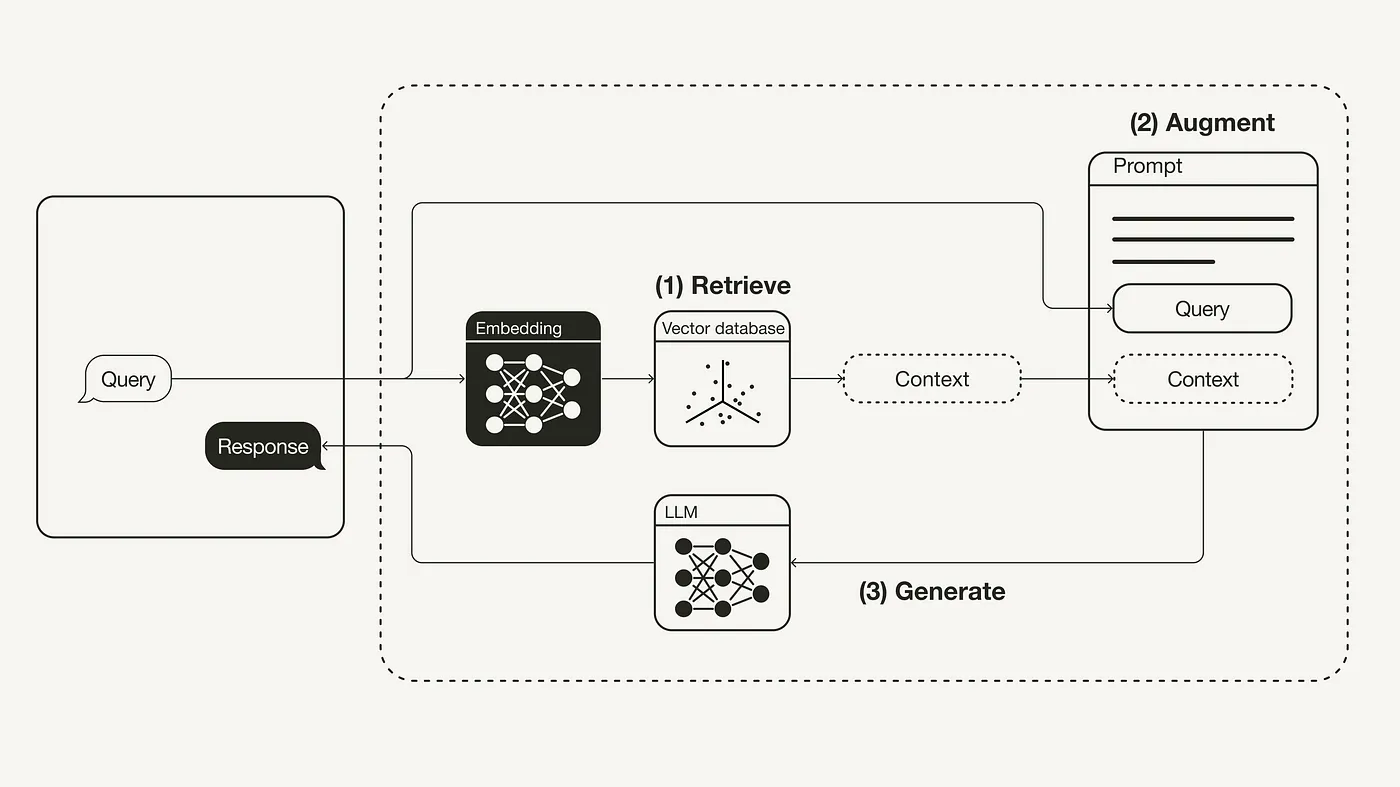
Retrieval-Augmented Generation (RAG) is the concept to provide LLMs with additional information from an external knowledge source. refer here(Retrieval Augmented Generation)
In simple terms, RAG is to LLMs what an open-book exam is to humans. In an open-book exam, students are allowed to bring reference materials, such as textbooks or notes, which they can use to look up relevant information to answer a question.
RAG Implementation
This section implements a RAG pipeline in Python using an OpenAI LLM in combination with a Weaviate vector database and an OpenAI embedding model. LangChain is used for orchestration.
Prerequisites
Make sure installed the required Python packgaes:
langchainfor orchestrationopenaifor the embedding model and LLMweaviate-clientfor the vector database
$ pip install langchain openai weaviate-client