Retrieval Augmented Generation
Retrieval Augmented Generation(RAG) is a way that can make pre-trained LLM to generate more accuracy text which is origin from paper here.
RAG is a hybrid framework that integrates retrieval models and generative models to produce text that is not only contextually accurate but also information-rich.
Method
RAG is a method that combines two types of memory:
- that's like the model's prior knowledge
- that's like a search engine, making it smarter in accessing and using information.
RAG pushes the boundaries of what is possible in NLP, making it an indispensable tool for tasks like question-answering, summarization, and much more.
In a nutshell, the retrieval model acts as a specialized 'librarian,' pulling in relevant information from a database or a corpus of documents. This information is then fed to the generative model, which acts as a 'writer,' crafting coherent and informative text based on the retrieved data. The two work in tandem to provide answers that are not only accurate but also contextually rich.
Two Main Components
The RAG framework has two main components:
- the retrieval model
- the generative model
These components can be variously configured and fine-tuned, depending on the application. Together, they make the RAG model an incredibly flexible and powerful tool.
Retrieval Model
Retrieval models act as the information gatekeepers in the RAG architecture. Their primary function is to search through a large corpus of data to find relevant pieces of information that can be used for text generation. Think of them as specialized librarians who know exactly which 'books' to pull off the 'shelves' when you ask a question. These models use algorithms to rank and select the most pertinent data, offering a way to introduce external knowledge into the text generation process. By doing so, retrieval models set the stage for more informed, context-rich language generation, elevating the capabilities of traditional language models.
Retrieval models can be implemented through a number of mechanisms. One of the most common techniques is through the use of vector embeddings and vector search, but also commonly used are document indexing databases that utilize technologies like BM25 (Best Match 25) and TF-IDF (Term Frequency — Inverse Document Frequency).
Generative Models
Once the retrieval model has sourced the appropriate information, generative models come into play. These models act as creative writers, synthesizing the retrieved information into coherent and contextually relevant text. Usually built upon Large Language Models (LLMs), generative models have the capability to create text that is grammatically correct, semantically meaningful, and aligned with the initial query or prompt. They take the raw data selected by the retrieval models and give it a narrative structure, making the information easily digestible and actionable. In the RAG framework, generative models serve as the final piece of the puzzle, providing the textual output we interact with.
Technical Implementation
Source Data
The starting point of any RAG system is its source data, often consisting of a vast corpus of text documents, websites, or databases. This data serves as the knowledge reservoir that the retrieval model scans through to find relevant information. It's crucial to have diverse, accurate, and high-quality source data for optimal functioning. It is also important to manage and reduce redundancy in the source data
Data Chunking
Before the retrieval model can search through the data, it's typically divided into manageable "chunks" or segments. This chunking process ensures that the system can efficiently scan through the data and enables quick retrieval of relevant content. Effective chunking strategies can drastically improve the model's speed and accuracy: a document may be its own chunk, but it could also be split up into chapters/sections, paragraphs, sentences, or even just “chunks of words.” Remember: the goal is to be able to feed the Generative Model with information that will enhance its generation.
Text-to-Vector Conversion (Embeddings)
The next step involves converting the textual data into a format that the model can readily use. When using a vector database, this means transforming the text into mathematical vectors via a process known as “embedding”. These are almost always generated using complex software models that have been built with machine learning techniques. These vectors encapsulate the semantics and context of the text, making it easier for the retrieval model to identify relevant data points. Many embedding models can be fine-tuned to create good semantic matching; general-purpose embedding models such as GPT and LLaMa may not perform as well against scientific information as a model like SciBERT, for example.
Links between Source Data and Embeddings
The link between the source data and embeddings is the linchpin of the RAG architecture. A well-orchestrated match between them ensures that the retrieval model fetches the most relevant information, which in turn informs the generative model to produce meaningful and accurate text. In essence, this link facilitates the seamless integration between the retrieval and generative components, making the RAG model a unified system.
If you need a place to keep text documents to use in RAG solutions, you need a vector database! Vector Search on Astra DB is now available. Doc here!
Challenges and Limitations
Complex of Debug
One of the most evident drawbacks is the model complexity. Given that RAG combines both retrieval and generative components, the overall architecture becomes more intricate, requiring more computational power and making debugging more complex.
Preparation of Data
Another difficulty is in data preparation: making available clean, non-redundant text and then developing and testing an approach to chunk that text into pieces that will be useful to the generative model is not a simple activity. After all of that work, you then have to find an embedding model that performs well across a potentially large and diverse amount of information!
Engaging a Large Language Model (LLM) often requires prompt engineering - while RAG is able to better inform the generative model with high-quality retrieved information, that information often needs to be correctly framed for the LLM to generate high-quality responses.
Lastly, there's the performance trade-off. The dual nature of RAG—retrieving and then generating text—can increase latency in real-time applications. Decisions must be made about how to balance the depth of retrieval against the speed of response, especially in time-sensitive situations.
Practices for RAG Implementation
Data Preparation
The cornerstone of a successful RAG implementation is the quality of your data. It is imperative to invest time and effort into data cleaning and preprocessing to enable optimal model performance. This entails text normalization, which involves standardizing text formats, and entity recognition and resolution, which helps the model identify and contextualize key elements in the text. Also, eliminating irrelevant or sensitive information such as personally identifiable information (PII) is crucial to align with privacy standards.
Regular Updates
RAG thrives on real-time or frequently updated information. Establish a robust data pipeline that allows for periodic updates to your data source. The frequency of these updates could range from daily to quarterly, depending on your specific use case. Automated workflows to handle this process are highly recommended. Frameworks such as the open-source Langstream can combine streaming with embedding models, making this task easier.
Output Evaluation
Measuring the model's performance is a two-pronged approach. On one end, manual evaluation offers qualitative insights into the model's capabilities. This could involve a panel of domain experts scrutinizing a sample set of model outputs. On the other end, automated evaluation metrics such as BLEU, ROUGE, or METEOR can provide a quantitative assessment. User feedback, if applicable, is another powerful tool for performance assessment.
Continuous Improvement
The world of AI is ever-evolving, and continuous improvement is not just an ideal but a necessity. This could mean anything from updating the training data, revising model parameters, or even tweaking the architectural setup based on the latest research and performance metrics.
End-to-End Integration
For a smooth operational experience, integrating your RAG workflows into your existing MLOps protocols is essential. This includes following best practices in continuous integration and continuous deployment (CI/CD), implementing robust monitoring systems, and conducting regular model audits.
By adhering to these best practices, you not only optimize the performance of your RAG model but also align it well with broader machine learning and data management ecosystems. This holistic approach ensures that you extract the maximum utility from your RAG implementations.
Start up with Langchain
Refer: here[1]
LangSmith stores many good application trained models can be directly pull to use. You can test and upload yourself model or data on it them call them directly through Python.
Two Components
Indexing: a pipeline for ingesting data from a source and indexing it. This usually happen offline.
Retrieval and generation: the actual RAG chain, which takes the user query at run time and retrieves the relevant data from the index, then passes that to the model.
Indexing
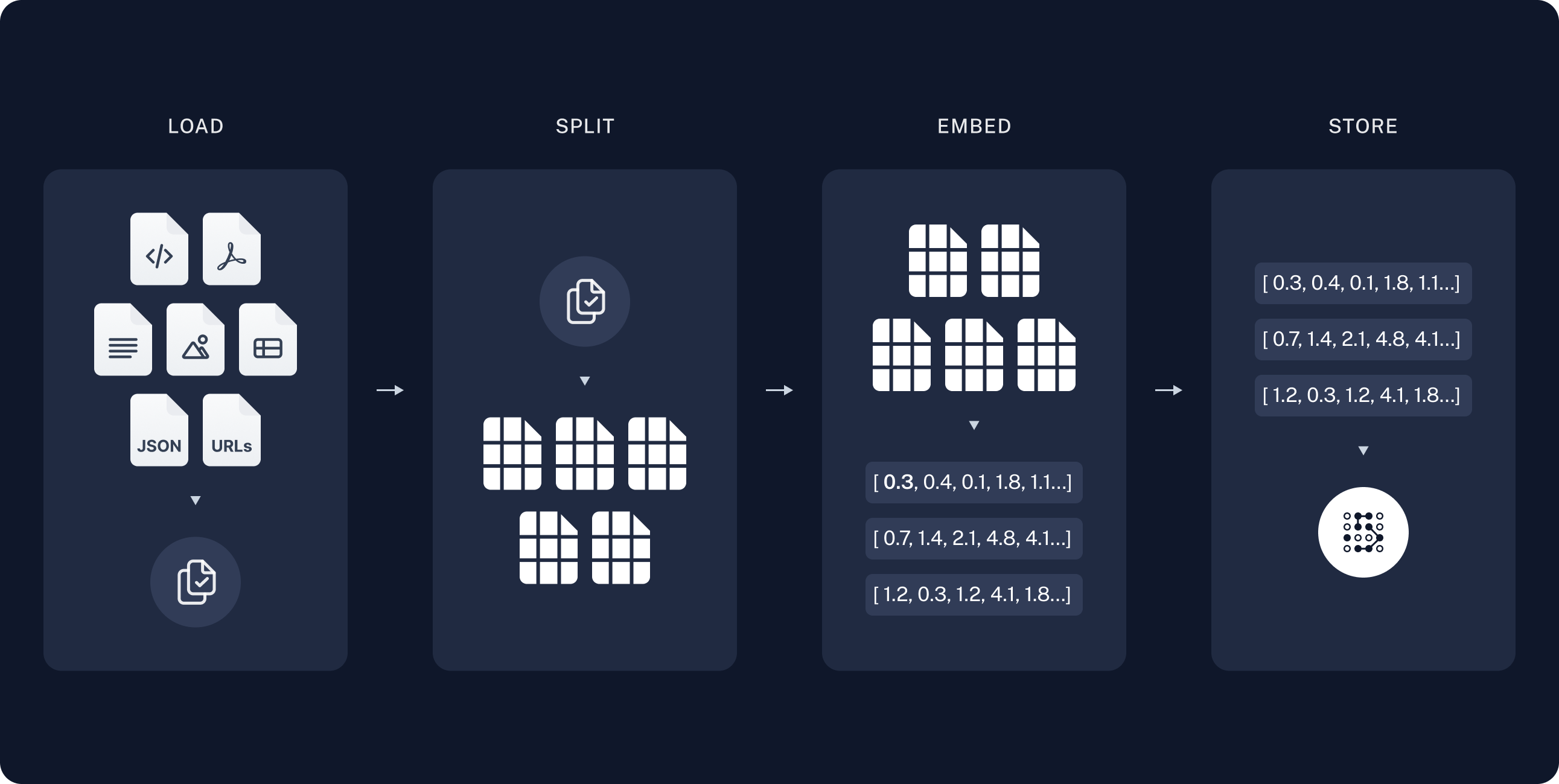
- Load: First we need to load our data. We'll use DocumentLoaders for this.
- Split: Text splitters break large
Documentsinto smaller chunks. This is useful both for indexing data and for passing it in to a model, since large chunks are harder to search over and won't in a model's finite context window. - Store: We need somewhere to store and index our splits, so that they can later be searched over. This is often done using a VectorStore and Embeddings model.
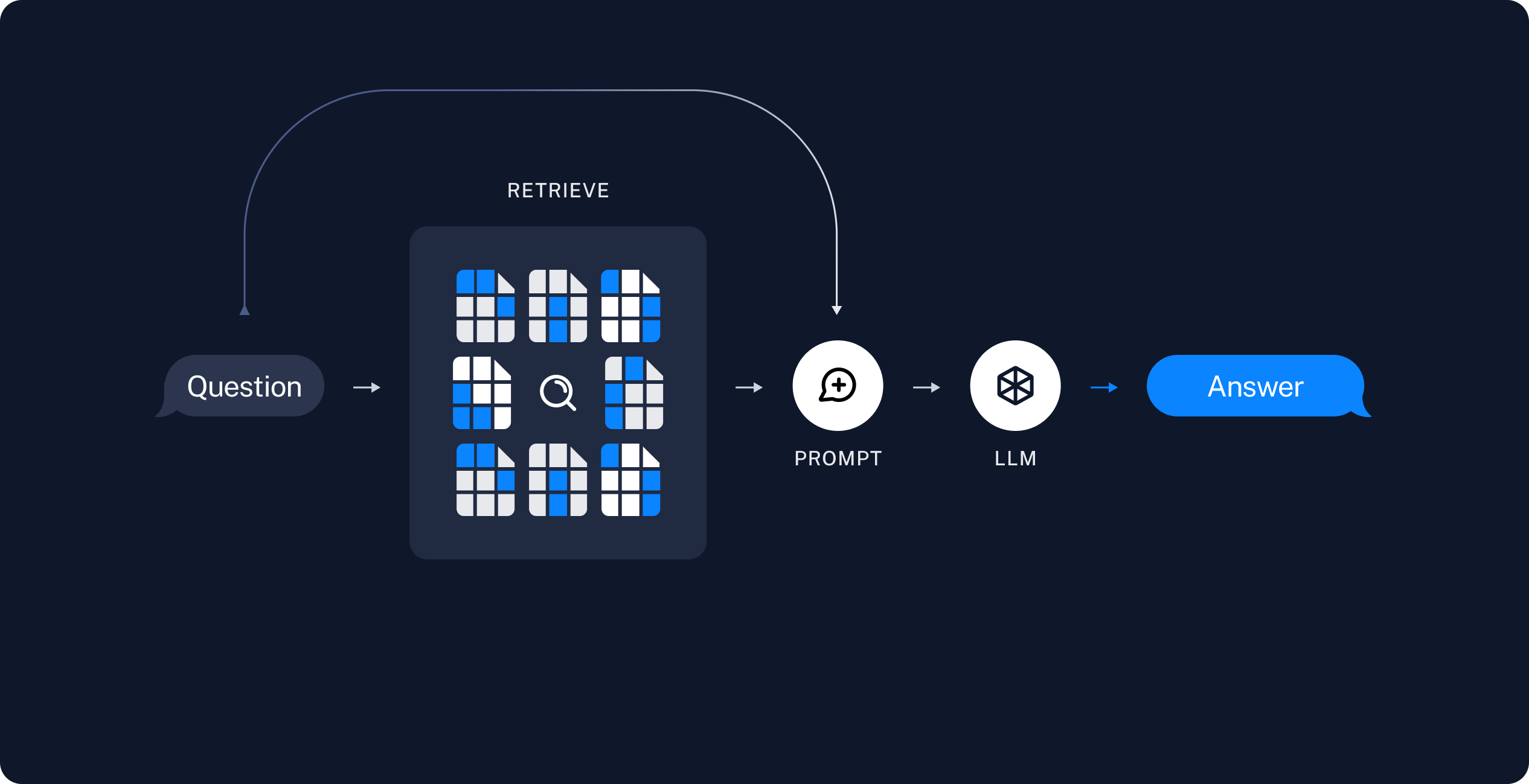
Retrieval and generation
- Retrieve: Given a user input, relevant splits are retrieved from storage using a Retriever.
- Generate: A ChatModel / LLM produces an answer using a prompt that includes the question and the retrieved data
Load
Loading data from website or JSON, any other files. Here is an example to load website info:
from langchain.document_loaders import WebBaseLoader
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs={
"parse_only": bs4.SoupStrainer(
# check the website's class to find which part you want
class_=("post-content", "post-title", "post-header")
)
},
)
docs = loader.load()